A Word on Data Management
Data represent a fundamental output of the scientific process. Accompanying metadata are indispensable for their interpretation and should be considered inseparable from data. Successfully managing data provides many benefits in daily routines, but also helps to satisfy journal, institutional and funder requirements.
"Good research data management is not a goal in itself, but rather the key conduit leading to knowledge discovery and innovation, and to subsequent data and knowledge integration and reuse." – H2020 FAIR Data Guidelines
Organizing, storage, backup, and sharing of research data are essential data management skills for a modern researcher. Faced with ever increasing data quantity, multiplying with each transformation, model iteration, or quality control steps, data management is a daunting task for many. Developing a plan and refining it throughout the project can be helpful by including some practices, such as utilizing a file naming convention, folder structure, automated backup schedules, code annotation etc.
In addition, many publishers of scientific journals require that data underlying the publication be available (COPDESS), preferably in domain repositories. Open Access requirements of funding agencies may be similar, but may extend to other data collected in the course of the project. Ideally, any project will have a research data management plan (RDMP) containing provisions on how project data will be preserved and shared, and where questions such as licensing the data are addressed. A RDMP is a common requirement of major funding agencies in Germany and the EU. Researchers in Germany are expected to comply with the German Research Foundation (DFG) Guidelines for Safeguarding Good Scientific Practice. A guideline on archiving implies that primary data as the basis for publications shall be securely and comprehensively stored for at least ten years at the institution of their origin, and that research data, materials and information, methods and the software used should be made available with a comprehensive description of workflows. The Guidelines for Research Data Management at the GFZ German Research Centre for Geosciences underline the provision of research data for further use as a service that not only benefitting science but also society as a whole. The key feature of reusable data are detailed metadata containing a description of how data was obtained and what happened to them over time.
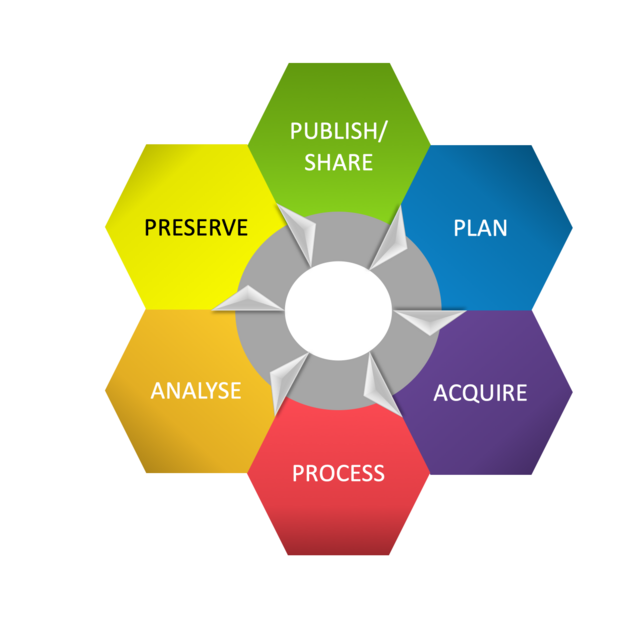
Data Management Roadmap
The Data Management Roadmap is a tool to help researchers cope with the challenges of data management. Research data management (RDM) is a process which begins before the data is collected and in most cases should conclude with data being shared publicly. This process is termed the Data Life Cycle. According to each stage of the life cycle, handling research data may require different RDM practices, although some are common to all.
The goal of RDM is to produce self-describing and reusable data sets. The Data Management Roadmap helps you navigate the RDM process by outlining sensible RDM practices. It is based on the US Geological Survey Science Data Lifecycle Model and the DataONE Data Management Primer.
This Roadmap was created by GeoDataNode, a project funded by the German Ministry for Education and Research, in response to support needs in research data management identified in the survey of data management practices conducted in 2018.
DM Roadmap - Details
Goals
- I have a description of the project, including hypotheses and planned data generation
- I have aligned my data documentation with a domain repository metadata standard
- I have a documented strategy to organize my data, including file naming conventions, directory structure, formats, and a back-up schedule
Recommendations
1. What data will you generate and use?
Considering your hypotheses and sampling plan, describe the rationale of the methods and analyses, the sample collection or measurements you will undertake and any other relevant information. Include a description of the instruments used, sources of already existing data that you plan to use in your project and what types of IT resources you will require.
2. Choose a repository
Choosing a data repository most suitable for your research domain and data type will help guide your documentation process in all stages of the life cycle. A domain repository usually will provide instructions for data submission and a documentation scheme (i.e. metadata standard) for your data as well as information on licenses. Inquire with your colleagues which repository would be suitable for your data. GFZ Data Services is a research data repository for the geosciences domain.
3. Data organization
Describe how your data will be organized. You should describe the file formats you will use, but also consider a file naming convention, a directory (folder) structure, version control, and how data is organized within a file (e.g. table). Consider creating a list of units, abbreviations, categorical variables and other parameters used. If you are relying on tables, decide on an appropriate field delimiter.
4. Document data
Check with your colleagues for existing community standards on data documentation. In addition, please take a look at the required metadata of the research data repository you would like to use for publishing your data. Especially domain repositories are often complementing international metadata standards with domain vocabularies.
5. Data safety
Create a plan for preventing data loss or equipment failure. Consider an automated back-up schedule and different back-up locations.
6. Sharing data
Consider conditions for sharing data within the project and with other collaborators beyond the project team. The conditions of sharing may differ for any of these groups, for example when and how data may be shared with project partners or publically released. Particular care must be taken when data contain personal information, i.e. sensitive data.
7. Data management budget
Consider who will be responsible for implementing your RDMP, what digital infrastructure may be required, and what expenses will occur (e.g. when depositing data in a repository). Your project proposal should address estimated costs for data management.
Goals
- Store raw data separately
- Use consistent file collection, i.e. utilize a template
- Have a list of parameters, units, variables, formats and locations
Recommendations
Utilizing consistent data collection and documentation methods improves (re-)usability of data. Regardless of later processing steps, it is of utmost importance to keep raw data separate, well-documented and safe.
- Create a location for storing raw data. This will ensure that you can always go back to the beginning if things go wrong.
- A template for data collection would enable consistent data collection and ensure that relevant contextual information are collected, even by others.
- Use only plain text for column headers, file names and data to ensure readability by various software.
- Keep file formats consistent, i.e. do not re-arrange columns etc.
- Document the data collection procedure and the file contents.
- Explain how files are formatted, define parameters, units, the decimal delimiter, abbreviations or codes you might have used (for missing values, detection limits etc.). Place these information in a README.txt file or a metadata standard accompanying the data.
- Use explanatory file names which describe the project, location, file contents and date.
- Use stable, non-proprietary file formats such as csv or tab separated text.
- If you are sampling multiple locations, create a locations table.
- if you have physical samples, please contact us for inquiry and provision of IGSN (International Generic Sample Numbers). IGSNs uniquely identify physical samples are citable in articles and link to an online sample description
Goals
- Have a flowchart or workflow of processing steps
- Document processing steps
- If a script is used, use comments to document processing steps
Recommendations
Data Processing refers to structured activities which alter or integrate data and may result in visual and statistical summaries, or data ready for further analysis. The documentation of data processing steps is part of a data publication metadata record, so make sure to keep track of processing documentation. If available, follow a standard procedure in your discipline. If you need to create your own processing sequence, formalize it in a workflow document. Whenever possible, use open data formats (e.g. TIFF, txt, netCDF). If you are automating processing with a script, make sure the script is well commented, and consider illustrating the sequence with a diagram or flowchart. A good documentation of processing steps increases transparency and is crucial for reproducibility and reusability of processed data. Here are some examples of data processing steps.
1. Transformation
Transforming data refers to format conversions and/or reorganizing data that does not affect the meaning of the data but facilitates display and analysis (e.g. in different software environments).
2. Validation
Data validation is a quality control step to ensure data are fit for use. Typically values can be compared to adjacent measurements, natural limits, or contextual constraints (e.g. another variable affecting the measurement). Rather than removing values, consider using quality flags or codes in a separate field to indicate data quality. These quality flags should be part of your documentation.
3. Subsetting
Subsetting data occurs whenever you select parts of a larger dataset, exclude or filter values to create a smaller set of data suitable for a particular need.
4. Summarization
Summarizing data is a data reduction step where data may be aggregated, grouped or where statistics are derived.
5. Derivation
Data derivation creates new values not present in the original data.
6. Integration
Combining data into new data sets through merging, stacking, or concatenating data are activities associated with data integration.
Goals
- Document analytical procedure and the analytical environment
- Document experiment setup, input parameters etc. to provide for reproducibility
- If possible, automate using well-documented scripts
Recommendations
Analyses are activities in which data are explored and assessed, hypotheses tested, insight and conclusions are drawn. Maintaining documentation in the analysis stage is crucial to ensure transparency and reproducibility and is required in the methods section of a scientific article or the metadata of a data publication.
If you are relying on software, document version and environment of the software you are using for the analyses. Here are some example activities in the analysis stage of the data life cycle:
1. Statistical analysis
Deriving patterns, identifying trends, making generalizations, and estimating the uncertainties associated with the data falls under the umbrella of statistical analyses.
2. Visualization
Visualization refers to graphical representation of data in graphs, charts and maps, for example. Visualization aids understanding and communicates relationships within the data.
3. Spatial analysis
Spatial analysis or statistics cover any technique in which topological, geometric or geographic properties and relationships of spatial data or data attributes are investigated.
4. Image analysis
Image analysis refers to activities used for detection of objects and patterns within digital images. Some examples are classification of land cover, or the digitalization of features.
5. Modelling
Modeling usually involves software tools used to simplify or make abstractions of a natural system. Models enable the description and prediction of such systems. Some examples are climate models, basin models, and magnetic field models.
Goals
- Data for long-term storage must be accompanied by documentation explaining acquisition, processing and analysis
- Use persistent, non-proprietary formats for data
Recommendations
Data preservation refers to procedures aimed at keeping data for longer periods of time. As data should be ready for re-use later, it must be accompanied by rich metadata. The German Research Foundation states that primary data as the basis for publications shall be securely stored for ten years in a durable form in the institution of their origin. There are two terms that are often used interchangeably: data archive and data repository. Institutions or agencies may operate archives – digital infrastructure where data may be stored with the accompanying metadata.
Repositories are archives, but also provide additional services, such as accessibility of data, persistent identification of data (i.e. DOI), data property rights identifier, and in the case of domain repositories, quality control (curation) of metadata in a discipline specific metadata format. In either case, persistent, non-proprietary data formats should be used whenever possible to ensure re-usability in the long term.
Goals
- Data ready for publication is accompanied by documentation explaining acquisition, processing and analysis
- Data are in a persistent, non-proprietary format
- Questions regarding property rights have been cleared within project
Recommendations
Making data available for re-use is an important part of the data life cycle. The best practice for data sharing is a data publication through a domain repository and it is the recommended practice by GFZ. Data should be in an open format and must be accompanied by documentation explaining acquisition, processing and analysis steps.
A domain data repository will provide a discipline specific metadata schema for describing the data. Domain repositories provide a quality control process for metadata. The data publication process with a domain repository should result in data being discoverable and in most cases openly accessible, although access can be restricted for a set period of time (embargo). A published data set will be citable and have a unique and persistent identifier (e.g. DOI).
Goals
- Check with project for existing guidelines, requirements, infrastructure and responsibilities
- Automate backup, ideally to multiple locations
- Sensitive data must be handled with special care
Recommendations
Throughout the project lifetime, data must be protected from accidental loss and unauthorized access. Check if there are existing guidelines within your group or project regarding backup and data security and who may be responsible.
Backups will protect your data from loss due to hardware failure, human error, or cyber threats. Good data management will also consider physical and cybersecurity. Automated backups – ideally at multiple locations and media, will protect you from data loss. When creating a backup, also include the metadata. Check that backups are identical to the original (e.g. checksum).
When handling sensitive data (e.g. …), consider encryption, or secure locations, and make sure that your anti-virus software is current. Whenever possible, sensitive data must be stored behind a firewall.
Goals
- Describe acquisition, processing, analysis and quality control steps
- Describe parameters, formats, resolution of data set
- Describe context and stakeholders involved in data collection
Recommendations
In order to maintain data quality and provide for re-usability of data, describing the context of data collection, parameters measured, and actions taken upon the data, is a critical aspect of data management throughout the data life cycle. Documentation of data makes it possible to understand and use the data in the future. Digital metadata standards should be used for describing data sets and can be obtained at a domain repository. The following are some considerations when describing data, e.g., modified after Strasser et al. (2012):
1. Context
- Data set name
- List of file names in data set
- Date of last modification
- Pertinent companion files
- List of related or ancillary data sets and samples
- List of samples used for the analyses (IGSN)
- Software used to prepare/read data
- Data processing steps
2. Personnel and stakeholders
- Who collected or created the data and respective PIDs (e.g. ORCID)
- Who should be contacted about data
- Sponsors, funding agencies etc.
3. Scientific context
- Why were the data collected?
- What data were collected?
- What instruments (including serial numbers) were used
- Environmental conditions during collection
- Location of data collection
- Spatial resolution
- Date of data collection (if appropriate)
- Temporal resolution
- Standards and calibrations used
4. Information about parameters
- How each was measured or produced
- What units are used
- What format are the data stored
- Precision, accuracy, uncertainty
- Information about data
- Definitions of codes and abbreviations used
- Quality control measurements
- Known limitations on data use (e.g. uncertainty, sampling problems)
Goals
- Define quality classification criteria
- Describe quality control workflow
- Include data quality flags in data files
Recommendations
Data quality management refers to workflows and procedures used to assure proper data collection, handling, processing, usage and maintenance at all stages of the data life cycle. Quality control refers to data defect detection, such as spurious data, incorrect classification, missing values or transformation errors.
Consider utilizing quality flags for data contained within the data files themselves. This way, a user may decide what data is fit for use. Documenting quality control measures should include a description of data quality flags, classification criteria, and any procedures performed to make data suitable for use.